Informatica
Noțiuni introductive
Informatica – definiție
Este știința care se ocupã cu studiul reprezentãrii și prelucrãrii informației;oInformatica este strânsã legatã de dispozitivele automate de calcul (computere); cu toate acestea, calculatorul este mai degrabã un instrument al informaticii decât un obiect de studiu în sine.
Informatica- domenii
Existã numeroase domenii ale informaticii (informatica teoreticã, informatica practicã, informatica tehnicã, inteligența artificialã etc.), fiecare cu subdomenii proprii;oÎn cadrul acestui curs ne vom concentra asupra algoritmilor și a programãrii calculatoarelor.
Algoritmul – definiție
Este o strategie (metodã, procedurã) de rezolvare a unei probleme sau, de cele mai multe ori, a unei categorii de probleme;oOrice algoritm pleacã de la un set de date de intrare și, dupã un numãr de pași în care acestea sunt prelucrate, obține un set de rezultate (date de ieșire);oDeși este un concept matematic, noțiunea de algoritm poate fi extinsã la probleme din viața de zi cu zi (o rețetã culinarã poate fi privitã ca un algoritm, la fel manualul de utilizare al unui aparat etc.).
Proprietãți ale algoritmilor
Claritatea:orice algoritm trebuie exprimat astfel încât sã nu lase loc de interpretãri – orice persoanã sau dispozitiv automat trebuie sã îl poatã urma pas cu pas;
Generalitatea: orice algoritm trebuie sã rezolve o categorie de probleme, sau o problemã generalã, nu un caz particular (Algoritmul lui Euclid determinã cel mai mare divizor comun dintre oricare douã numere naturale);
Finititudinea: orice algoritm trebuie sã se încheie dupã un numãr finit de pași.
Algoritmi reprezentați prin scheme logice
Schemele logice (organigrama)
O schema logica este un desen care descrie multimea pasilor ce constituie un proces de calcul. Folosind schemele logice devine posibila reprezentarea secventelor care compun codul unui program. Schemele logice utilizeaza in acest scop sageti de legatura intre diferite simboluri geometrice care simbolizeaza tipurile de actiuni.
Schemele logice sunt folosite pentru dezvoltarea de software; ele sunt realizate inainte de a fi scris programul sursa, cu scopul de a detalia logica solutiei si de a simplifica munca de scriere a codului. Folosite in acest scop, schemele logice functioneaza ca:
1. Mijloc de documentare
2. Instrument de analiza
3. Mijloc de comunicare
Schemele logice sunt, prin natura lor, diagrame simbolice. Astfel, ele sunt compuse din simboluri care specifica operatii bine-definite. Fiecare simbol este unic ca forma si reprezinta o anumita operatie, avand pozitia fixata in interiorul schemei logice si fiind conectat la simbolurile de inaintea lui si de dupa el. Aceasta multime de simboluri creeaza succesiunea pasilor care definesc lista operatiilor pe care le contine programul (Figura 5.1).
Presupunem ca programul actioneaza asupra unor date aflate pe o banda de intrare, iar rezultatele sint inregistrate pe o banda de iesire. Modul de acces si organizare pentru mediile de intrare si iesire este cel secvential.
Sunt admise urmatoarele instructiuni:
1. Instructiunea START. Executia unui program incepe intotdeauna cu aceasta instructiune.
2. Instructiunea STOP. Efectul acestei instructiuni este terminarea executiei programului.
3. Instructiunea de citire, care determina citirea a n valori de pe banda de intrare si inscrierea lor in locatiile de memorie rezervate pentru variabilele a1, , an.
4. Instructiunea de scriere, care determina inscrierea pe banda de iesire a valorilor memorate in locatiile de memorie rezervate pentru valorile a1, , an.
5. Instructiunea de atribuire, al carei efect consta in evaluarea expresiei e si inscrierea rezultatului in locatia de memorie rezervata variabilei v.
6. Instructiunea de ramificare. Efectul instructiunii consta in continuarea calculelor mergand pe sageata corespunzatoare unei alternative unice din mai multe.
Schematic aceste instructiuni se reprezinta in modul urmator:
1. Instructiunile START si STOP:
Simbolul utilizat pentru aceste instructiuni este blocul terminal (Figura 5.2). Blocul terminal este folosit pentru a indica inceputul si sfarsitul unei scheme logice. O conventie in alcatuirea schemelor logice impune ca numai doua blocuri terminale sa poata fi plasate intr-o schema logica, unul la inceputul si celalalt la sfarsitul acesteia.
Aceeasi conventie impune si ca blocurile terminale folosite sa fie obligatoriu marcate prin cuvintele START si STOP, corespunzatoare blocului de inceput si respectiv de sfarsit al schemei logice. Blocurile terminale astfel marcate sunt cunoscute si sub numele de bloc START, respectiv bloc STOP.
|
|

Figura 5.2 Blocurile START si STOP
2. Instructiunile de intrare / iesire:
Realizarea operatiilor de intrare si de iesire este marcata prin folosirea blocurilor de intrare / iesire. Pentru a indica operatia de intrare se folosesc cuvintele READ sau INPUT, iar pentru a indica operatia de iesire se folosesc cuvintele WRITE sau OUTPUT.
Pentru standardizare, vom folosi numai una dintre aceste optiuni, si anume cuvantul READ pentru operatia de intrare (introducere de date), respectiv cuvantul WRITE pentru operatia de iesire (scriere de date). Aceste notatii sunt apropiate de limbajul C++, ceea ce usureaza o eventuala conversie a schemei logice in program C++. Se practica si o prescurtare, astfel incat blocurile de intrare / iesire astfel marcate sunt cunoscute si sub numele de blocuri READ, respectiv WRITE
cin << = Read
cout >> = Write
|
|

Instructiunea de atribuire (de calcul):
Blocul de calcul este folosit pentru a indica operatii de calcul – care presupun manipularea aritmetica a datelor, sau operatii de atribuire – care presupun , pe langa calcul, si mutarea datelor dintr-o locatie de memorie in alta.
Intr-un astfel de bloc de calcul se inscriu formule matematice, sau propozitii care precizeaza calculele ce urmeaza a fi efectuate
|
|
4. Instructiunea de decizie:
Blocul de decizie este folosit atunci cand vrem sa efectuam pasi diferiti, dependenti de o anumita conditie; cand conditia este adevarata vom efectua o secventa de instructiuni, iar cand conditia este falsa vom efectua o alta secventa de instructiuni. Este posibil si cazul in care conditia poate fi evaluata la mai multe valori posibile; atunci vom realiza operatii diferite pentru fiecare valoare in parte.
Astfel in program sunt introduse ramificatii, functie de evaluarea conditiei. In acest caz se poate opta pentru o varianta din mai multe posibile
![]()
 |
Vom numi schema logica o reprezentare grafica in care:
1. exista o unica instructiune START si o unica instructiune STOP
2. este alcatuita numai din instructiuni de tipul:
- STOP, START
- o citire sau o scriere
- o atribuire
- o ramificare
3. exista macar un drum care incepe cu instructiunea START si se termina cu instructiunea STOP
Schemele logice permit precizarea actiunilor algoritmului prin enunturi asociate simbolurilor grafice.
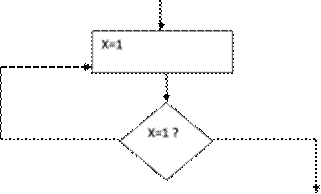
Definitia de mai sus nu poate elimina insa toate cazurile de nedeterminare a programelor, cum ar fi de exemplu o schema logica de felul celei din figura, care face ca programul sa cicleze pe aceste comenzi, adica sa se execute la infinit.
 |
Un exemplu de schema logica creata pentru a rezolva o problema este prezentat la sfarsitul acestei sectiuni .
Pentru a usura construirea si citirea schemelor logice s-a simtit nevoia ca in constructia acestora sa se foloseasca numai anumite configuratii obtinandu-se astfel scheme logice structurate, care respecta definitia enuntata mai sus. Aceste structuri sint specifice programarii structurate.
In maniera 'traditionala' de alcatuire a algoritmilor, realizarea diferitelor structuri de control se bazeaza pe utilizarea unor comenzi de salt conditionat si neconditionat, dand programatorilor o mare libertate in alcatuirea algoritmilor. Rezultatul a fost ca algoritmii contineau un numar important de salturi 'nedisciplinate' care ascundeau rationamentele, ingreunand intelegerea, testarea si modificarea programelor scrise pe baza lor.
Pentru a ocoli aceste neajunsuri, programarea structurata propune disciplinarea realizarii algoritmilor prin restrangerea structurilor de control utilizate la un anumit set redus de tipuri de structuri. Orice algoritm, oricat de complex, urmeaza a fi realizat numai printr-o combinatie de structuri din acest set, incluse una in alta.
Programarea structurata are la baza o justificare matematica furnizata de Böhm si Jacopini in 1966, cunoscuta ca 'teorema de structura', care precizeaza ca orice algoritm avand o intrare si o iesire poate fi reprezentat ca o combinatie de trei structuri de control:
- secventa de doua sau mai multe operatii (enumerare);
- alegerea unei operatii din doua alternative posibile (decizie);
- repetarea unor operatii atat timp cit o anumita conditie este indeplinita (ciclul cu test initial, iteratie).
Efectele structurilor descrise corespund unor procese ale rationamentului uman: enumerarea, decizia, iteratia, ceea ce face ca utilizarea lor in dezvoltarea algoritmilor sa fie deosebit de simpla si naturala.
O alta teorema care sta la baza programarii structurate este teorema de rafinare si descompunere; aceasta ne spune ca asezand intr-un nod al unei scheme logice o alta schema logica, rezultatul este tot o schema logica si faptul ca o schema logica poate fi descompusa in subscheme logice mai mici pe care se lucreaza separat ca apoi sa le reimbinam. Aceasta conduce si la un alt mod de programare, si anume la programarea modulara.
Dar problemele complexe din viata reala nu pot fi reprezentate totdeauna prin schemele logice care nu au posibilitatea de declarare a tipurilor, si de la un anumit nivel devin greu de urmarit – cand este vorba de rezolvarea unor probleme foarte complexe. In astfel de situatii se utilizeaza un alt limbaj de descriere al algoritmilor, si anume limbajul pseudocod.
Despre variabile
Prelucrarea datelor presupune stocarea acestora;o
“Containerele” în care se pãstreazã datele poartã numele de variabile și ni le putem imagina ca pe niște cutii în care la un moment dat putem depozita un singur obiect;o
Variabilele sunt folosite atât pentru pãstrarea datelor de intrare, cât și pentru reținerea unor rezultate (parțiale sau finale) obținute pe parcursul derulãrii algoritmului;
Fiecare operație de citire presupune și specificarea variabilelor în care vor fi pãstrate datele;oFiecare atribuire are forma: VARIABILÃ<= EXPRESIE(se citește “VARIABILÃIA VALOAREA EXPRESIE”).
Despre expresii
Expresiile sunt formate din operatori (+, -, *, ?, % etc.) și operanzi;
Operanzii pot fi variabile, constante sau alte expresii (plasate între paranteze);o
Exemple: 2*(5+x) : operatorii sunt * și +; pentru operatorul + operanzii sunt 5 (constantã) și x (variabilã), iar pentru operatorul * operanzii sunt 2 și 5+x (expresie).
Blocuri de decizie
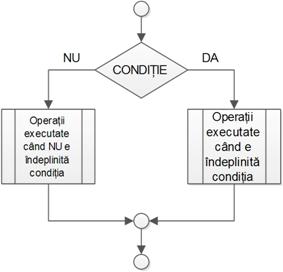
Apar acolo unde algoritmul se ramificã în funcție de verificarea unei condiții (expresie logicã, având valorile ADEVÃRAT sau FALS);
Întotdeauna ramura din dreapta va corespunde valorii “ADEVÃRAT” (“DA”, condiția este îndeplinitã), iar cea din stânga valorii “FALS” (“NU”, condiția NU este îndeplinitã);
Blocurile de decizie se folosesc și în cazul în care se dorește ca anumite operații sã se repete cât timp o anumitã condiție e îndeplinitã; în astfel de situații, ramura “DA” se va întoarce în schemã undeva deasupra blocului de decizie.
Blocuri de decizie simple
Apar acolo unde nu este necesarã repetarea anumitor operații;
Sunt simbolizate prin romburi, în interiorul cãrora apare câte o expresie logicã (condiție).
 |
Exemple de algoritmi reprezentați prin scheme logice
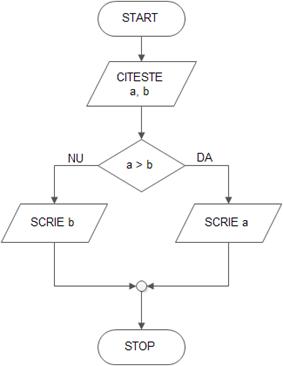
Maximul a douã numere
Se citesc douã numere naturale a și b (datele de intrare ale algoritmului);
Algoritmul va determina și afișa cea mai mare dintre valorile citite.
Maximul a douã numere varianta 1
În funcție de rezultatul comparãrii este afișat a sau b
 |
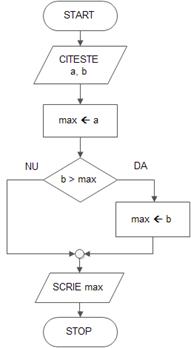
Maximul a douã numere varianta 2
În varianta a doua, pe lângã variabilele a și b, folosite pentru a reține cele douã numere citite, se utilizeazã o alta, numitã max;
Max va reține rezultatul final: inițial primește valoarea primului numãr citit (a), iar apoi, dacã b este mai bun max ia valoarea acestuia;
Aceastã a doua variantã oferã avantajul scalabilitãții (adicã poate fi adaptatã ușor pentru calculul maximumului a trei, patru, sau oricâte numere, cu condiția sã știm dinainte câte numere se vor citi)
 |
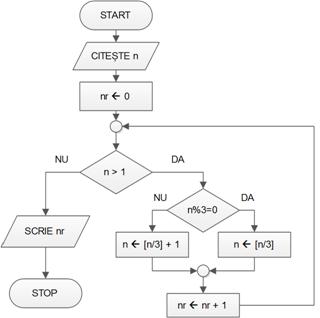
Gãsirea monedei false
Se dau n monede, dintre care se știe cã una ste falsã (e mai ușoarã decât toate celelalte)
Avem la dispoziție de asemenea o balanțã cu douã talere; pe fiecare dintre acestea se pot plasa oricâte monede;
Se cere un algoritm care sã determine numãrul minim de cântãriri necesare pentru a determina moneda falsã.
Fiecare cântãrire se poate încheia cu trei rezultate: talerul stâng atârnã mai mult, talerul drept atârnã mai mult sau cele douã talere sunt în echilibru;
Primele douã situații sunt simetrice și în fiecare dintre ele grupul monedelor suspecte se reduce la monedele de pe talerul care atârnã mai puțin;
Dacã avem echilibru, atunci moneda falsã se aflã printre monedele care nu au fost cântãrite;
Pentru a reduce grupul monedelor suspecte cât mai mult în cazul cel mai nefavorabil, vom împãrți monedele în 3 grupe aproximativ egale;
Dacã n (numãrul monedelor “suspecte”) este divizibil cu 3, atunci împãrțim monedele în 3 grupe egale numeric și indiferent de rezultatul cântãririi, reducem n la n/3;
Dacã n nu este divizibil cu 3, fie q = câtul împãrțirii cu rest a lui n la 3. Plasãm câte q+1 monede pe fiecare taler și astfel, în cazul cel mai rãu reducem grupul suspect la q+1.
Schema logicã alãturatã corespunde algoritmului descis în slide-ul anterior;
Se repetã procesul de cântãrire urmat de reducerea grupului suspect atâta timp cât n>1.
 |
Scheme logice cu operații repetitive sau secvențe repetive (ciclare)
De multe ori o schemã logicã repetitivã , presupune repetarea de un anumit numãr de ori a unor calcule , teste etc.
Pentru a efectua aceste secvențe de cod este necesarã crearea unei structuri repetitive.
Secvențe repetitive pot fi:
· cu numãr determinat de repetiții
· cu testarea continuãrii repetiției la inceput de ciclu
· cu testarea continuãrii repetiției la sfîrșitul ciclului.
O secvența repetitivã cu numãr determinat de repetiții este prezentatã mai jos.
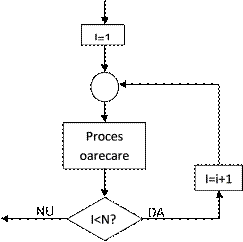 |
O astfel de schemã logicã se folosește atunci când avem de repetat niște operații de un numãr cunoscut de ori
Secventa repetitivã cu testul la început, este prezentatã în schema urmãtoare:
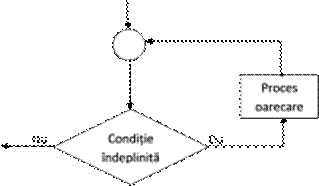 |
Schema logicã cu testul la început se aplicã atunci când nu știm numãrul de repetiții a operațiilor . Adicã se poate sã se execute de n ori sau nici o datã.
Secventa repetitivã cu testul la s, este prezentatã în schema urmãtoare:
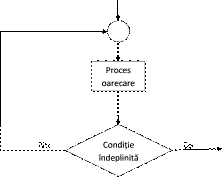 |
Secvența repetitiva cu test la sfârșit se executã cel puțin o datã.
Algoritmi reprezentați prin scheme logice și pseudocod
Pseudocodul
· Este un limbaj de nivel înalt cu ajutorul cãruia pot fi descriși algoritmii;o
· Deși folosește convenții structurale asemãnãtoare cu cele ale unui limbaj de programare, pseudocodul a fost creat mai degrabã pentru a fi înțeles și interpretat de cãtre oameni decât de cãtre calculatoare;
· Un program pseudocod nu poate fi interpretat sau compilat de cãtre un calculator, dar poate fi cu ușurințã “tradus” în limbaj de programare de cãtre un informatician.
Structuri de bazã în pseudocod și echivalentul lor în scheme logice
· Pentru citirea datelor, în pseudocod se folosește instrucțiunea:
 citește variabile
citește variabile
· Pentru afișarea expresiilor, se folosește:
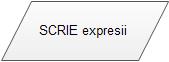
scrie expresii
Structuri de bazã în pseudocod și echivalentul lor în scheme logice
· Pentru atribuire, în pseudocod se folosește:
variabilã ← expresie 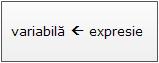
· Ca și în cazul schemelor logice, mai întâi se evalueazã expresia din partea dreaptã a sãgeții, apoi valoarea acesteia este reținutã de variabila specificatã în partea stângã.
Structuri de bazã în pseudocod și echivalentul lor în scheme logice
Echivalentul din pseudocod al blocurilor de decizie specifice schemelor logice este instrucțiunea “dacã”, având forma:
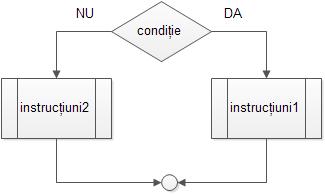
dacã condiție
{
instrucțiuni1
}
altfel
{
instrucțiuni2
}
Pentru structura repetitivã, în pseudocod existã mai multe variante pe care urmeazã sã le studiem;
· Structura repetitivã cu test inițial corespunde schemei logice alãturate și are forma:
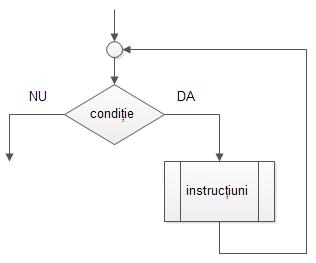
cât timp condiție
{
instrucțiuni
}
· Instrucțiunile subordonate vor fi executate atâta timp cât condiția e îndeplinitã (expresia logicã are valoarea “adevãrat”)
Algoritmul de determinare a maximului a n numere are în pseudocod forma de mai jos:
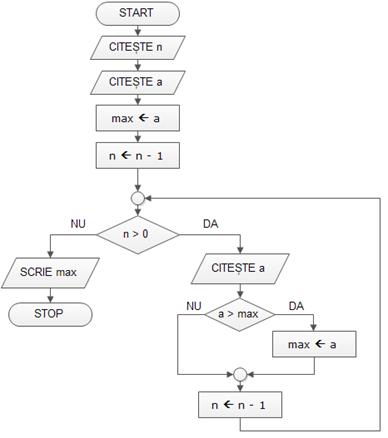 citește n
citește n
citește a
max ←a
n ← n – 1
cât timp n > 0
{
citește a
dacã a > max
{
max ← a
}
n ← n -1
}
scrie max
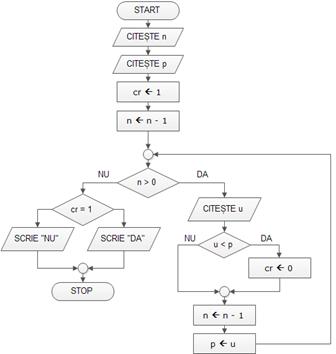 Algoritmul care verificã dacã un șir de n numere este ordonat crescãtor are în pseudocod forma de mai jos:
Algoritmul care verificã dacã un șir de n numere este ordonat crescãtor are în pseudocod forma de mai jos:
citește n
citește p
cr ← 1
n←n – 1
cât timp n > 0
{
citește u
dacã u < p
{
cr ← 0
}
n ← n -1
p ← u
}
dacã cr = 1
{
scrie “DA”
}
altfel
{
scrie “NU”
}
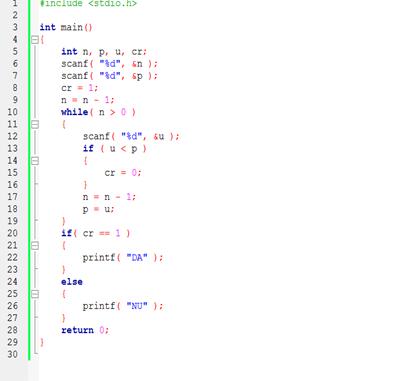
În algoritmul anterior se folosesc douã variabile: p, reprezentând penultimul numãr citit și u, corespunzãtor ultimului numãr citit;
De la al doilea pânã la cel de-al n-lea numãr citit se verificã dacã p ≤ u;
Dacã la un moment dat aceastã condiție nu mai e îndeplinitã, atunci șirul nu e crescãtor (variabila cr, inițializatã cu 1, devine 0);
Pentru a avea mereu în memorie ultimele douã valori citite, dupã fiecare comparare p îi ia locul lui u, urmând ca u sã devinã urmãtorul numãr citit.
1) Maximul și numãrul aparițiilor sale
Scrieți un program care sã rezolve urmãtoarea problemã:
· Se citesc n (numãr natural nenul, n<100) și apoi n numere naturale nenule având câte cel mult 9 cifre fiecare (numerele nu sunt neapãrat distincte);
· Se cere sã se afișeze cel mai mare dintre cele n numere citite și numãrul aparițiilor sale.
Algoritmul pseudocod de rezolvare a problemei are în pseudocod forma de mai jos, iar schema logicã se aflã în figura alãturatã:
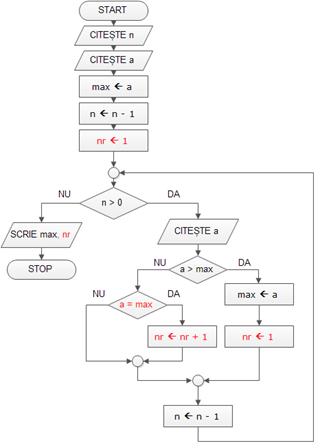 citește n
citește n
citește a
max ← a
n ← n – 1
nr ←1
cât timp n > 0
{
citește a
dacã a > max
{
max ← a
nr ← 1
}
altfel
{
dacã a= max
{
nr ← nr + 1
}
}
n ← n -1
}
scrie max, nr
Algoritmul anterior este construit pornind de la cel în care se determinã maximul dintre n numere, fãrã a lua în calcul numãrul aparițiilor acestuia;
Instrucțiunile scrise cu roșu sunt cele necesare pentru extinderea algoritmului.
Cele mai mari douã numere dintr-un șir
Scrieți un program care sã rezolve urmãtoarea problemã:
Se citesc n (numãr natural nenul, n<100) și apoi n numere naturale nenule având câte cel mult 9 cifre fiecare (numerele nu sunt neapãrat distincte);
Se cere sã se afișeze cele mai mari douã valori (nu neapãrat diferite) dintre cele n numere citite.
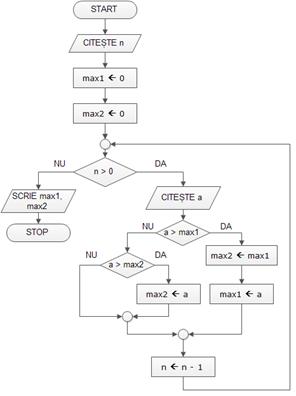 Algoritmul pseudocod de rezolvare a problemei are în pseudocod forma de mai jos, iar schema logicã se aflã în figura alãturatã:
Algoritmul pseudocod de rezolvare a problemei are în pseudocod forma de mai jos, iar schema logicã se aflã în figura alãturatã:
citește n
max1 ← 0
max2 ← 0
cât timp n > 0
{
citește a
dacã a > max1
{
max2 ← max1
max1 ← a
}
altfel
{
dacã a > max2
{
max2 ← max1
}
}
n ← n -1
}
scrie max1, max2
Algoritmul anterior se bazeazã pe faptul cã numerele citite sunt strict pozitive;
Folosind acest lucru, putem inițializa ambele variabile care vor conține rezultatele finale cu 0;
În general inițializarea trebuie fãcutã astfel încât sã nu afecteze rezultatul final: o sumã sau un contor vor fi inițializate cu 0 (element neutru la adunare), un produs cu 1 (element neutru la înmulțire), un minim cu o valoare mai mare deât toate cele care intrã în discuție, pentru ca dupã prima comparare acesta sã ia valoarea numãrului cu care a fost comparat;
Un maxim poate fi inițializat cu o valoare mai micã decât toate cele care sunt luate în discuție;
Fiecare dintre aceste variabile pot fi inițializate cu primul element al șirului;
Algoritmul folosește variabilele max1, pentru a reține cea mai mare valoare din șir și max2 pentru a doua cea mai mare valoare;
La citirea fiecãrui numãr a, acesta se comparã mai întâi cu max1;
În cazul în care a>max1, trebuie modificate atât max1, cât și max2;
Variabila max2 va prelua conținutul lui max1, iar max1 va deveni a;
Dacã a este mai mare doar ca max2, atunci valoarea sa va fi reținutã în max2.
Limbajul de programare C
Prezentare generalã a limbajului C
Prezentare generalã a limbajului Co
· C este un limbaj de programare creat la începutul anilor ’70 (1969 - 1973) de cãtre Dennis Ritchie;
· Deși este un limbaj de nivel înalt, care respectã principiile programãrii structurate, arhitectura sa conține elemente foarte asemãnãtoare instrucțiunilor cod-mașinã;
· Aceastã proprietate a fãcut ca C sã fie folosit pe scarã largã pentru crearea de software de bazã, incluzând sisteme de operare, browsere, drivere etc.;
· C nu este numai unul dintre cele mai folosite limbaje de programare din toate timpurile, ci și cel mai influent: C#, Java, Objective C, PHP, Python și multe alte limbaje au preluat construcțiile sale de bazã.
Etapele realizãrii unui program C
· Limbajul C este unul compilat, adicã programatorul scrie instrucțiuni specifice într-un fișier text, numit fișier sursã, cu extensia .c;
· Apoi un alt program, numit compilator ”traduce” textul respectiv (numit ”cod sursã”, sau pur și simplu ”sursã”);
· Se obține un alt fișier care poate fi înțeles și executat de cãtre sistemul de operare;
· Nu orice cod sursã compilat poate fi executat; existã fișiere cu extensia .c care sunt doar folosite de cãtre alte fișiere .c.
Structura unui program C
· Prin ”program C” vom înțelege un fișier sursã care poate fi executat;o
· În general programele C conțin o primã zonã, cu așa numitele instrucțiuni de ”precompilare” – în cazul programului alãturat:

#include <stdio.h>
· Aceste instrucțiuni indicã secvențe de cod care vor fi inserate în codul sursã (fãrã ca programatorul sã vadã codul inserat) sau înlocuiri care urmeazã sã fie fãcute în etapa de compilare;
· Biblioteca stdio.h conține funcții speciale pentru citirea și afișarea datelor – prin urmare instrucțiunea de includere a acesteia va fi practic prezentã în orice program pe care îl vom scrie în C
Programul alãturat conține douã instrucțiuni;

Prima dintre ele:
printf(”Hello world!\n”);
are ca efect afișarea pe ecran a
mesajului de salut corespunzãtor
(este un program devenit
standard pentru cel mai simplu program în orice limbaj);
· Prima instrucțiune NU este obligatorie și va lipsi probabil din urmãtoarele noastre programe;
· A doua instrucțiune:
return 0;
este obligatorie la sfârșitul funcției int main(), prin urmare va apãrea în toate programele pe
care urmeazã sã le scriem.
Citirea datelor în C
Pentru citirea datelor, în C se folosește funcția scanf:
scanf(”%format”, &variabila);
Exemplu:
int x;
scanf(”%d”, &x);
Pot fi citite mai multe variabile cu un singur apel al funcției scanf, chiar dacã variabilele sunt de tipuri diferite:
scanf(”%format1%format2”, &var1, &var2);
Exemplu:
int x;
double y; // variabila de tip real cu formatul lf
scanf(”%d%lf”, &x, &y);
Lista completã a formatelor pentru citire și afișare cu funcții din biblioteca stdio.h urmeazã sã fie studiate ulterior, odatã cu tipurile de date din limbajul C.
Afișarea datelor în C
Pentru afișarea datelor, în C se folosește funcția printf:
printf(”%format”, expresie);
Exemplu:
int x;
…
printf(”%d”, x+2);
Pot fi afișate expresii complexe, care sã conținã și mesaje de tip text cu un singur apel al funcției printf:
scanf(”text0%format1text1%format2text2”, expr1, expr2);
Exemplu:
int x;
double y; // variabila de tip real cu formatul lf
…
scanf(”x este egal cu %d, iar y+1 =%lf”, x, y+1);
Declararea variabilelor în C
Spre deosebire de scheme logice și pseudocod, în C fiecare variabilã trebuie sã fie declaratã înainte de a fi folositã;
Declararea presupune precizarea tipului și numelui variabilei:
tip numeVariabila;
Declararea are ca efect rezervarea unei zone de memorie (în memoria internã) care va fi identificatã cu ajutorul numelui variabilei;
Tipul variabilei va determina dimensiunea memoriei alocate și operațiile permise (de exemplu, pentru o variabilã de tip real, nu va fi permisã operația ”%” care determinã restul împãrțirii întregi);
Tipul poate fi unul simplu, predefinit (int, char, float, double etc.) sau unul definit anterior în cadrul programului;
Numele variabilei trebuie sã fie format din litere, cifre și caracterul underscore (_) și trebuie sã nu înceapã cu o cifrã
Instrucțiunea de atribuire în C
Atribuirea are în C urmãtoarea formã:
variabila = expresie;
Exemplu:
int x;
x = 18;
De fapt în C atribuirea nu este o instrucțiune propriu-zisã ci o expresie (care poate face parte din alte expresii) – acesta e un aspect asupra cãruia urmeazã sã revenim.
Instrucțiunea de decizie (alternativã) în C
Echivalentul din C pentru structura alternativã din pseudocod este pur și simplu o traducere în
englezã a acesteia (”dacã” se traduce prin ”if” și ”altfel” prin ”else”);
În plus, condiția va fi totdeauna plasatã între paranteze ; ca și în cazul pseudocodului, ramura
”else” poate lipsi
if (condiție)
{
instrucțiuni1
}
else
{
instrucțiuni2
}
Exemplu:
int x;
scanf (”%d”, &x);
if (x%2==0)
{
printf(”%d este par”, x);
}
else
{
printf(”%d este impar”, x);
}
Instrucțiunea repetitivã ”while”
Așa cum ”if” este pur și simplu o traducere a lui ”dacã” din pseudocod, instrucțiunea C ”while” este o traducere a lui ”cât timp”;
Secvența pseudocod de mai jos
cât timp condiție
{
instrucțiuni
}
corespunzãtoare schemei logice
alãturate se scrie în C în felul urmãtor:
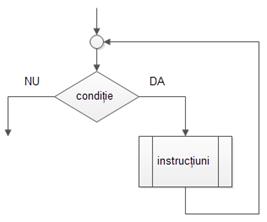
while (condiție)
{
instrucțiuni
}
”while” nu este singura structurã
repetitivã, dar orice algoritm poate fi
exprimat cu ajutorul ei;
Celelalte structuri și instrucțiuni
repetitive urmeazã sã fie studiate în
viitor
Exemple de algoritmi pseudocod și C echivalenți
Algoritmul de determinare a maximului a n numere are în pseudocod forma de mai jos, iar
în C cea din imaginea alãturatã:
 citește n
citește n
citește a
max ← a
n n – 1
cât timp n > 0
{
citește a
dacã a > max
{
max ← a
}
n ← n -1
}
scrie max
Algoritmul care verificã dacã un șir de n numere este ordonat crescãtor are în pseudocod forma de mai jos, iar în C cea din imaginea alãturatã:
citește n
citește p
cr ←1
n ← n – 1
cât timp n > 0
{
 citește u
citește u
dacã u < p
{
cr ← 0
}
n ← n -1
p ← u
}
dacã cr = 1
{
scrie “DA”
}
altfel
{
scrie “NU”
}